BPF 简史
Contents
从一个有意思的漫画说起
在开始我们的话题之前,我们可以欣赏下面几幅漫画:

这幅漫画从侧面说明了为什么 Linux 社区想要发明 eBPF 的动机:希望让 Linux 内核可编程。此处的可编程并不是让用户去修改 Linux 内核,而是让用户以一种学习成本极低的方式将自己的逻辑安全地插入内核,从而让用户可以快速给内核定制逻辑。
虽然 Linux 内核是开源世界诞生的奇迹,有着无与伦比的生态系统,但是其高耸的开发门槛也让新手望而却步:
-
Linux 内核从 1991 年由 Linus Torvalds 在社区发布以来,已历经近 20 年的演化迭代,其代码规模已非个人所能彻底掌握。目前的 Linux 内核代码整体代码规模已经超过了 2700 万行(这还只是 2020 年的统计数据,如今只会更加庞大)。Reddit 上有一张图很好地说明了这一演变过程:
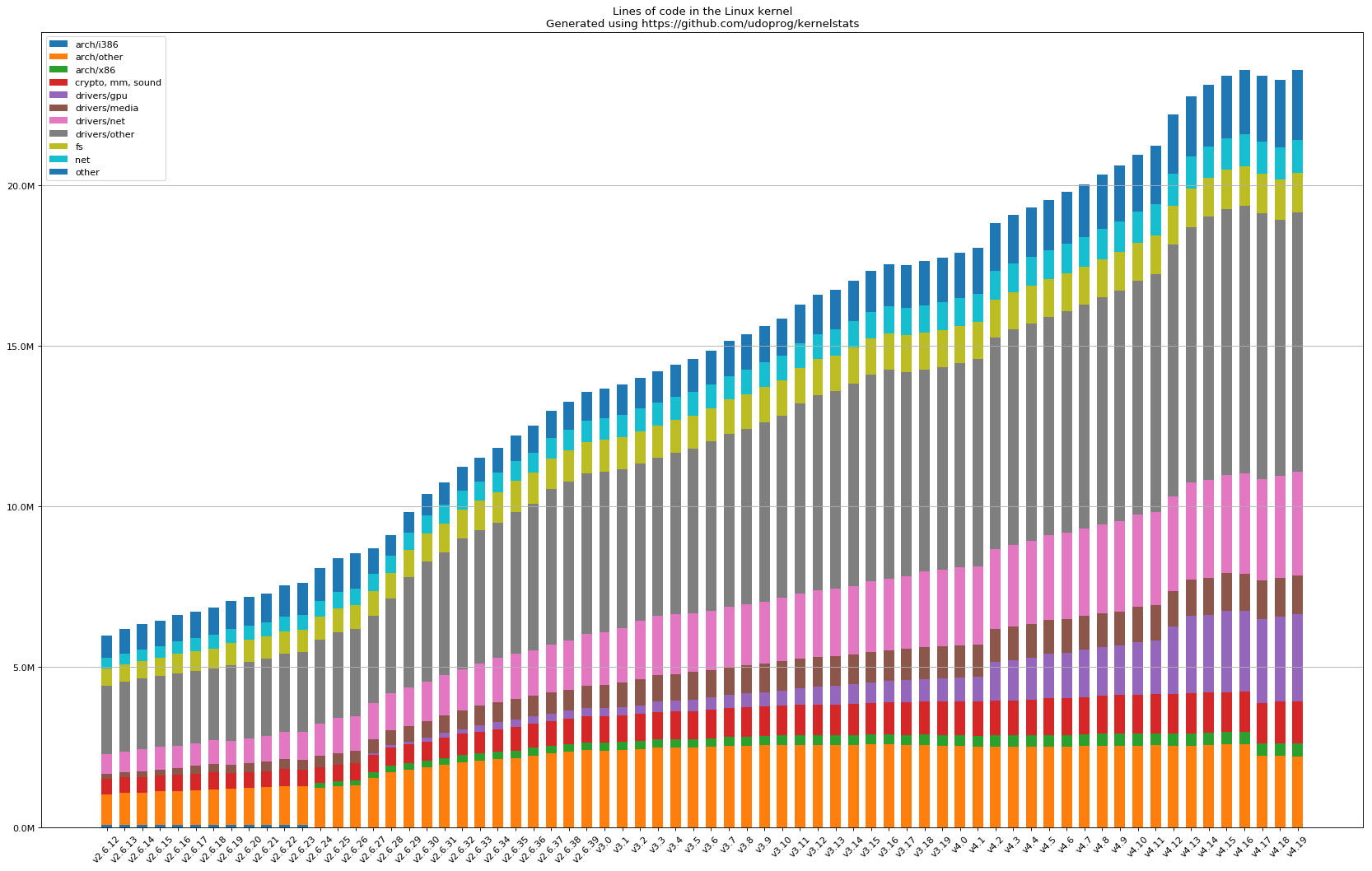
-
Linux 内核是一个典型的用 C 语言编写的宏内核,虽然内部的模块解耦进行了非常多精巧的设计,但是想要快速读懂内部逻辑并进行修改仍非一件易事。用户使用 C 语言必须非常小心,处处提防着会不会出现内存问题。不过很好的是,Linux 社区一直致力用引入 Rust 来提升 Linux 内核的开发效率;
-
与目前流行的 GitHub 开源模式不同,Linux 内核的开发模式有着其独特的文化,内核黑客们更喜欢用邮件来交流问题,以 Linus 为代表的内核权威会仔细地 Review 每一个 Commit ,把控着每一个 Feature 的引入,如果这个代码提交不符合 Linux 内核的架构设计原则,将有可能会长达数年都无法合入主干。所以,想要在 Linux 内核里有所创新,这是一件极其困难且周期漫长的事情;
因此,如果你想在 Linux 内核中增加一点新的 Feature 或者立志成为一个合格的 Linux 内核开发者,你都必须经过长时间的磨练:仔细地通读某个模块的代码;积极地与社区交流,熟悉社区文化;小心翼翼地在内核中添加代码并做实验…..所以,Linux 内核开发者是很稀缺的程序员,他们通常富有经验且在内核届摸爬滚打多年(你很难看到非常年轻的 Linux 内核开发者)。
但是,有了 eBPF 技术,这些或许会有所改变:

有了 eBPF 技术,用户可以用非常简单的方式(相较于开发内核代码)来将自己的代码插入到内核的运行逻辑中。至于内核是如何实现 eBPF 技术,我们将会在后续章节中慢慢介绍。
正是由于 eBPF 技术的各种神奇的特性,几大巨头公司纷纷在这一领域开发了各种各样的项目。就在今年,以 Facebook、Google、Isovalent、Microsoft 和 Netflix 为首的几家公司,联合成立了 eBPF Foundation(此处可能很多人对 Isovalent 这家公司不熟悉,其实这家公司的代表产品就是 Cilium,其主要开创者也是资深的 Linux 内核开发者和 eBPF 模块的维护者):

这其实是一个激动人心的时刻:标志着这门技术正逐渐成熟并被广为人知(比如我们可以联想一下 CNCF 的创立过程)。
性能优化届大神 Brendan Gregg 在他的演讲中,曾形象地将 eBPF 比喻成 Linux 的超能力:
Brendan Gregg: …super powers have finally come to Linux…
接下来就让我们追根溯源,看看 Linux 的超能力是如何诞生的吧 !
BPF 与 CSPF 的历史
两篇上古时期的论文
BPF 诞生于这篇 1992 年经典的论文,而 BPF 的全称为:
BSD Packet Filter
后续渐渐又将 B 简化为 Berkeley。正如这篇论文所说,BPF 是想要设计一种更高性能的 Packet Filter。那么 BPF 是与谁做比较来显得性能很高 ?答案就是 CSPF,即这篇论文(由 CMU 发表于 1987 年的 SOSP 上)所设计的 Packet Filter。我们在读 BPF 这篇论文之前,最好先读通读一下 CSPF 的设计,因为 BPF 的诞生很大程度都受到了 CSPF 的启发。
cBPF 和 eBPF
这里需要简单讲一下 cBPF 和 eBPF 两个词汇的差异。
首先,内核很早就有了 BPF 技术(最早源于 BSD,后移植于 Linux 内核),这是 Linux 为过滤网络包所设计的一个简易的内核虚拟机模块,我们常用的 tcpdump 就是基于 BPF 技术,此时的 BPF 又称 Classic BPF,即 cBPF。然后,内核开发者通过扩展原先的 BPF 技术,让这门古老的技术焕发新的生命力,故称为 eBPF(Extended BPF)。紧接着,内核开发者们又把内核中 cBPF 和 eBPF 的逻辑进行了合并,从而共享同一份逻辑实现。因此,当我们提及 BPF 时,其实就是 eBPF。由于 BPF 这个词同时包含了 cBPF 和 eBPF,所以一般用 BPF 来形容这门技术会更加准确。我们接下来都会不加区分地使用 BPF 和 eBPF 这两个词汇。
BPF 诞生背后的 CSPF
CSPF 整篇论文说白了就是:在内核中增加一个可用户自定义编程的 Packet Filter,而这个 Packet Filter 就是 CSPF。这样一来,我们可以将包过滤(论文又称为 Demultiplexing)的动作在内核中完成后再将最终的数据投递给用户进程。这种设计不仅可以保证包过滤的性能,又可以有用户层编程的灵活性,而这个核心思想也一直贯穿于后续的 BPF 技术的演变中。
在当年,TCP/IP 协议还未彻底统治网络,用户还是有需求需要自己实现网络协议。假设我们在用户层实现一个网络协议,并运行起一个 Demux 进程:每次网络包到达内核后,由于内核并不知道这个数据包的协议(即不知道需要把这个数据包具体路由到哪个进程),所以内核此时需要通过 Demux 进程来实现这一决策逻辑。下图展示了这一过程:
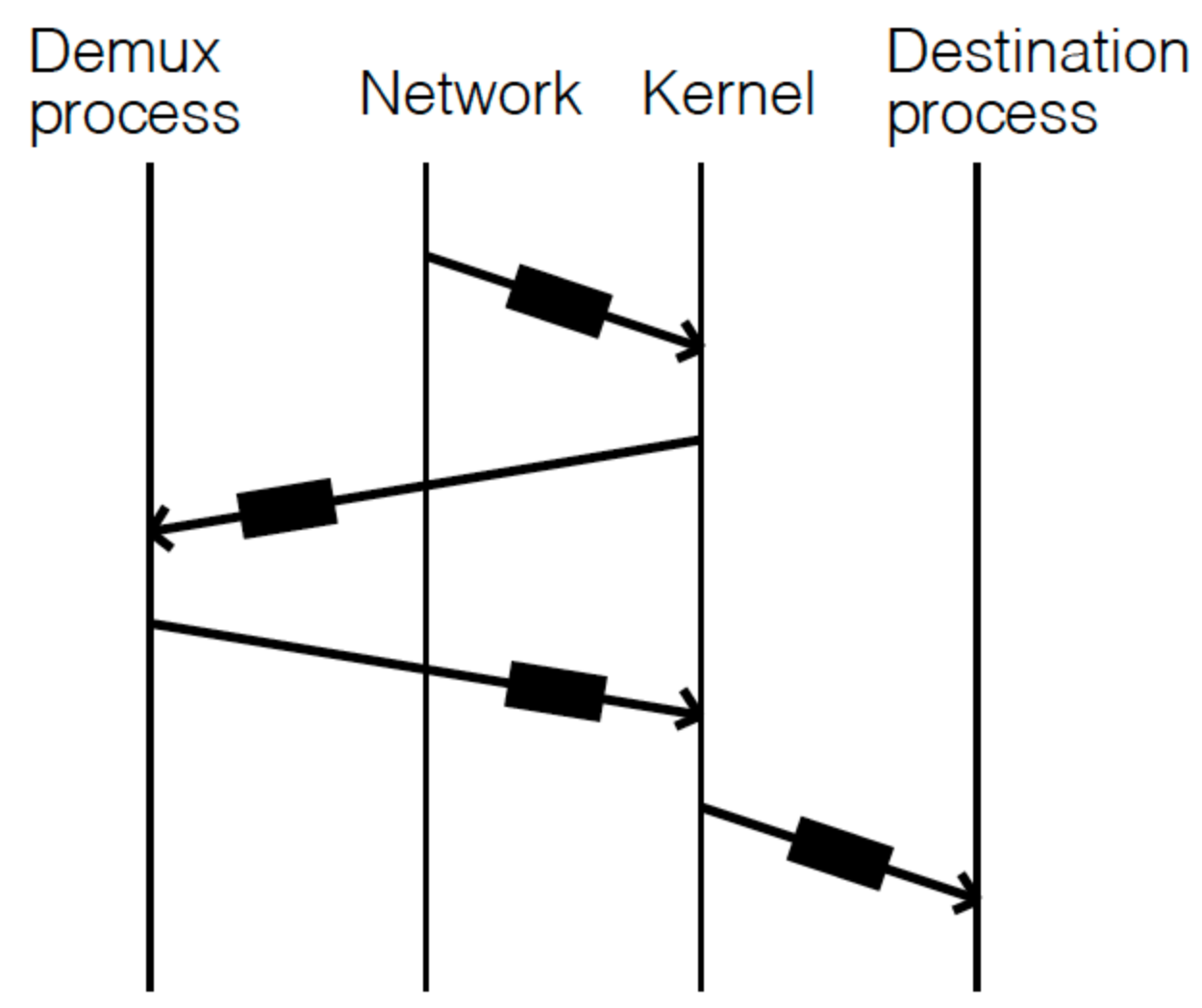
- 网络设备接收到数据包之后,将其拷贝给内核;
- 内核通知 Demux 进程,并将数据包从内核层拷贝到用户层,让其做出 Demux 的决策;
- Demux 进程告诉内核应该将数据包传给哪一个用户进程(这里应该还是会有相应的拷贝动作);
- 内核将数据包拷贝给相应的目标进程;
很显然,整个过程充满了网络包的拷贝,无疑性能将很糟糕。
为了提升性能,我们还是希望有一个 flexible kernel-resident demultiplexer,这样一来,整体流程就变成:
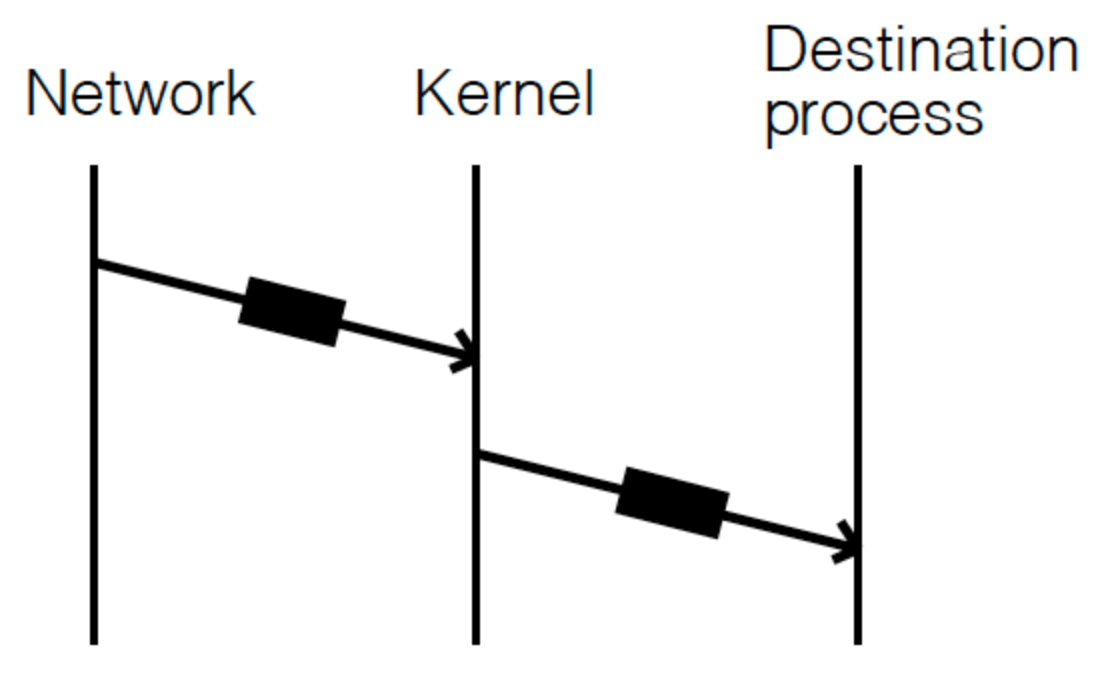
用户以可编程的方式将协议的信息告诉给内核的 Packet Filter,内核执行完 filter 指令后将其投递给对应的目标进程。这样一来,内核无需感知特定的协议实现,只需要维护一个通用的 Packet Filter 即可。之所以需要可编程,原因还是网络协议是无法预定义的,我们需要利用可编程的能力支持各种各样的网络协议。顺便提一句,Packet Filter 最早是出现于 1976 年 Xerox Alto(没错,就是那个大名鼎鼎的为乔布斯提供了 GUI 创意的施乐实验室所研发的通用型电脑)。
为了在内核中实现这个 Packet Filter,论文设计了一个基于 stack 的虚拟机(顺便提一句,目前很火的 WebAssembly 也是一门基于 stack 的虚拟机),我们可以称之为 CSPF。用户可以用 CSPF 提供的指令集(filter language)进行编程,然后将指令加载入 CSPF 进行执行。从现在的眼光来看,CSPF 提供的 filter language 非常简单:
-
每次都从 stack 上 pop 两个操作数进行执行,再将结果 push 回 stack。如果一系列操作下来,如果栈顶值非零,则该 packet 将被 accepted。
-
每条指令由两个 16-bit word 组成,如下所示:

第一个 Word 前 10 bit 表示 binary operator,后 6 bit 表示 stack action。其中 binary operator 就是所谓的布尔操作,如下所示:
除了 NOP 之外,所有的 binary operator 都会从 stack 上 pop two words,并将相应的结果 push 回 stack。栈顶元素即为 T1,而紧随其后的即为 T2,结果即为 R。对于 ADN / OR / XOR 来说,值非零即为 true。
而 stack action 则更为简单,如下所示:

为了能够立即返回,还有如下的 short-circuit 的 binary operator:

上面这 4 个 binary operator 都是进行
R := (T1 == T2)操作,但是不同的 operation 会根据不同的 result 进行返回。比如 CAND,如果结果为 false,则立刻返回;而 CNAND 则是相反的行为。
接下来,我们用一个论文中提及的简单例子来描述一下 CSPF 指令集是如何实现用户逻辑。
假如有一个 Pup 协议包,它长这样:
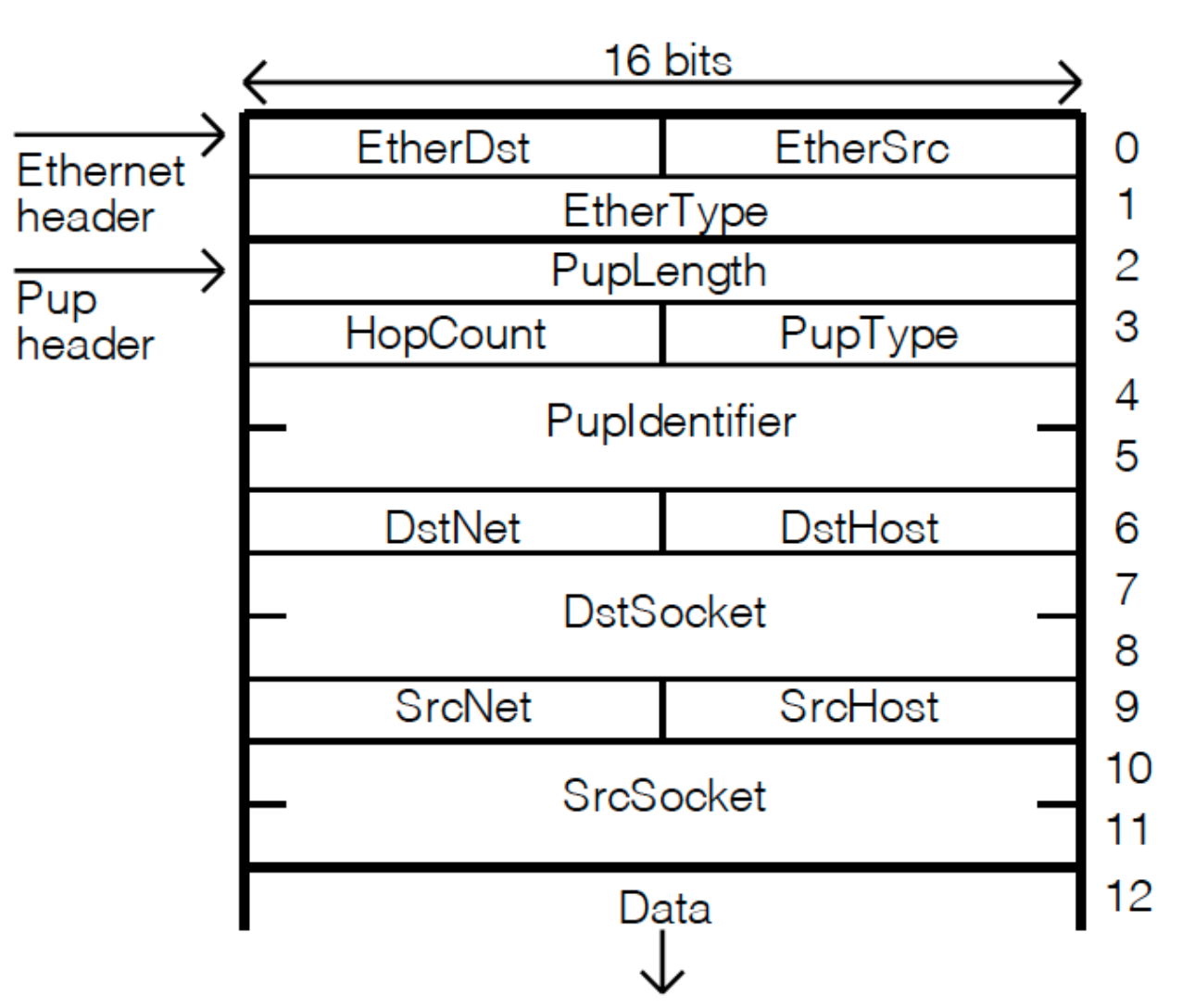
如果此时我们想只接收 Pup Types 从 1 到 100 的数据包,那么使用 CSPF 的 filter language 我们可以这样描述:
|
|
执行到 LE 之后,此时 stack 应该是这样:
|
|
此时我们将执行两条 AND 来获取最终的求值结果。
CSPF 最终在 4.3 BSD 系统用 C 语言实现。由于虚拟机逻辑相对比较简单,所以核心逻辑大约为 2000 行 C 代码。
BPF 的设计
BPF 的整体架构
BPF 与 CSPF 的大体架构类似,如下图所示:
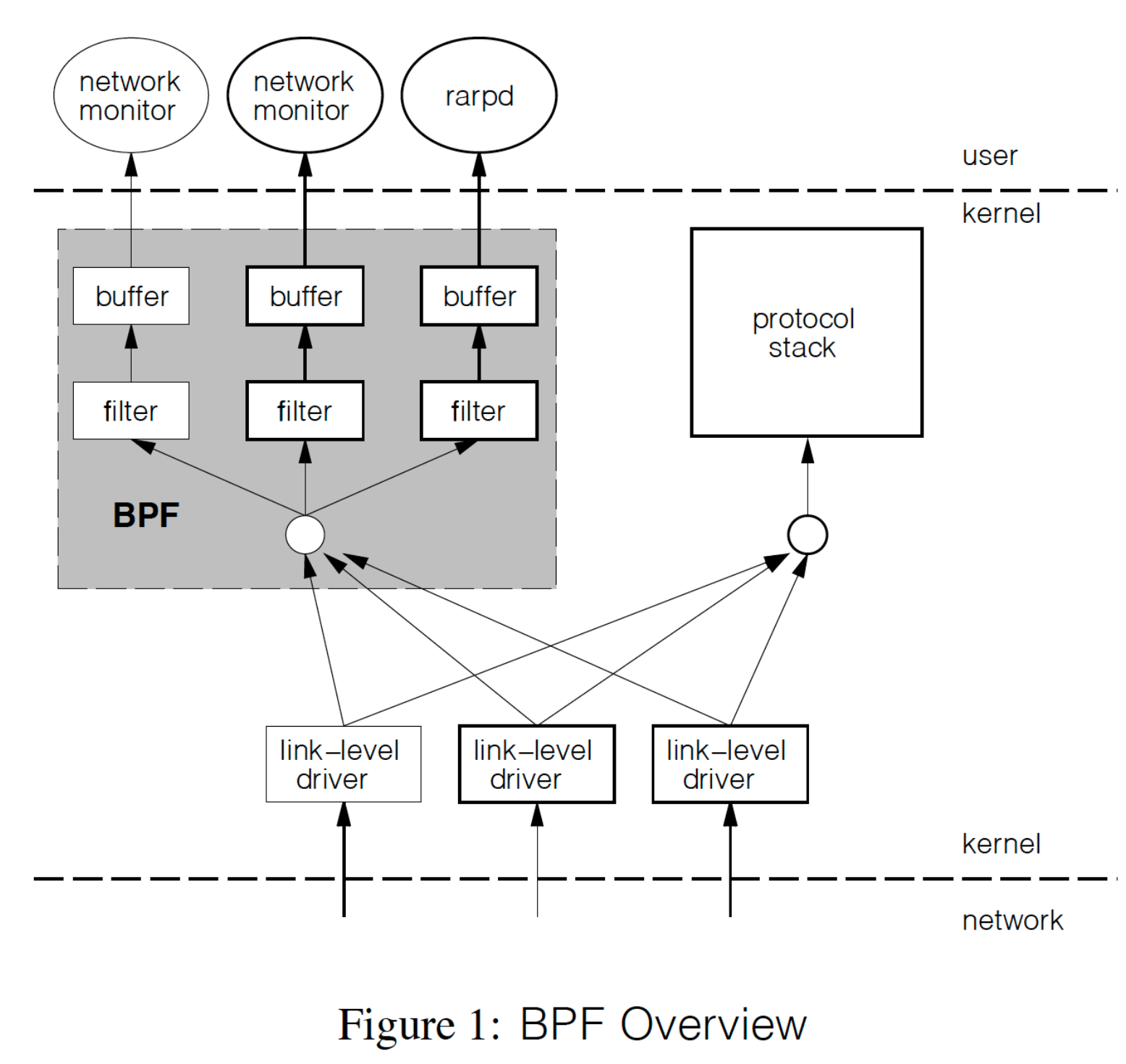
- 正常情况下,当网络设备驱动收到一个 packet 的时候,是直接送给协议栈;
- 当 BPF 监听某个网络设备时,packet 会先送给 BPF(tap),BPF 会通过 filter 判断这个包是否要给 application,然后将其 copy 进 buffer 里,让上层用户来读取;
BPF 最大的创新之处就是提供了一个比 CSPF 性能更强(20 倍性能差异)的基于 register 的虚拟机,而这个虚拟机设计正是后续所有 BPF 技术演化的基础。
两种不同的 Filter 模型
Packet Filter 其实本质上是一个 Boolean Valued Function,即是一个求值结果为 True 或 False 的函数。我们可以用两种模型来进行实现:
- Boolean Expression Tree:将求值的过程抽象称一个 Tree,每个节点是一个 Boolean 操作,而根结点是 AND 或者 OR ,这种模式可以自然映射为 stack machine,而这也是 CSPF 所采用的抽象模型;
- DAG:或者也可以叫 Control Flow Graph(CFG),即将求值过程抽象为一张图,节点同样是 Boolean 操作,而边表示控制转移,其实 DAG 比较像我们在做 if-else 操作。这种模型可自然映射为 register machine,也是 BPF 所采用的模型;
从计算上来看,这种两种模型是等价的,但实现上性能差异很大。
CSPF 模型制约性能最大的问题就是会有重复计算。在有些场景下,其实有些节点没必要计算。虽然可以提供短路计算来缓解这问题,但是有些东西是内在的,比如网络协议通常需要解析包头才能获得后续的信息,由于每个叶子都代表某个 field 且相互间独立,所以常会有重复计算。
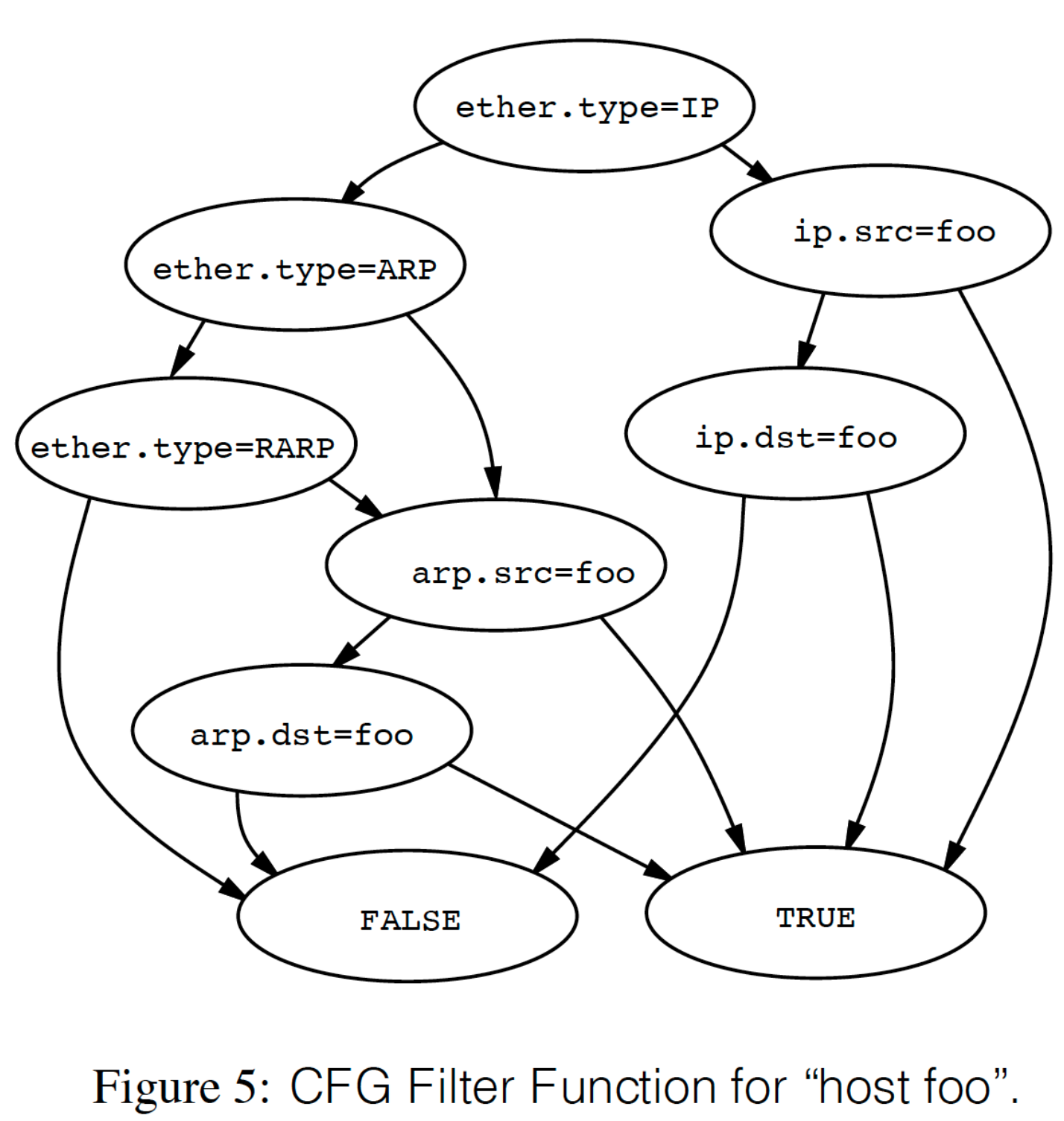
让我们来看这么一个场景:接受协议有 IP、ARP 和 RARP 中目标或者源地址有 foo 的包。
这个典型的 Packet Filter 转换为 DAG ,则为(左分支为 no,右分支为 true):
而如果转化为 Tree 模型,则为:
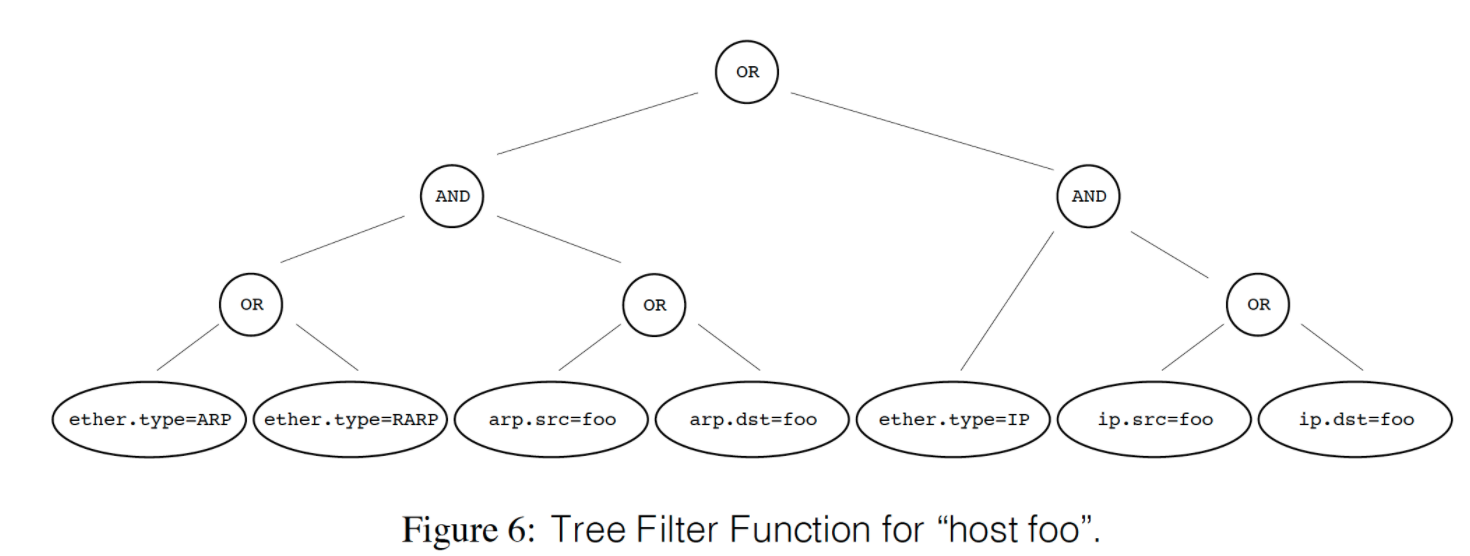
此处为了求解最终的值,这里 6 个 boolean operation 需要遍历整棵树,从而从直观上可以感受到与 DAG 计算量上的差异。
所以,从本质上来看,BPF 程序最终都将转换成一个 DAG并由内核来执行这个 DAG。
BPF 指令集设计
BPF 虚拟机从设计上有如下约束:
- 协议无关,其实就是把输入当成 byte 流;
- 通用,指令可以满足大多数场景;
- 对 packet 数据的引用要尽可能小,比如我们只需要访问原始 packet 一次就够。通常来说,我们都需要取出 packet 中的不同 field 来做比较,我们可以将一些 field 放到寄存器里;
- 解码只需要一个简单的 C switch 就够;
- 虚拟机的寄存器可映射为物理机的寄存器;
基于上述的设计约束,BPF 设计了一个基于 register 的虚拟机指令集,包括:
- accumulator:这是一个特殊的 32 位寄存器;
- index register:在下文的汇编中通常以 x 出现,其实就是寄存器;
- scratch memory store:内存的某个存储空间;
- 隐式的 program counter
所有的操作可归纳为以下几种:
- LOAD 指令:将 value copy 进 accumulator 或者 index register。copy 的数据源可以是:某个 offset 的 packet 数据、packet 长度等;
- STORE 指令:将 accumulator 或者 index register 的值 copy 进 scratch memory store;
- ALU 指令:执行算术或者逻辑运算;
- BRANCH 指令:根据比较来改变执行流;
- RETURN 指令;
- 其他指令;
每个指令都有其固定的 format,如下所示:
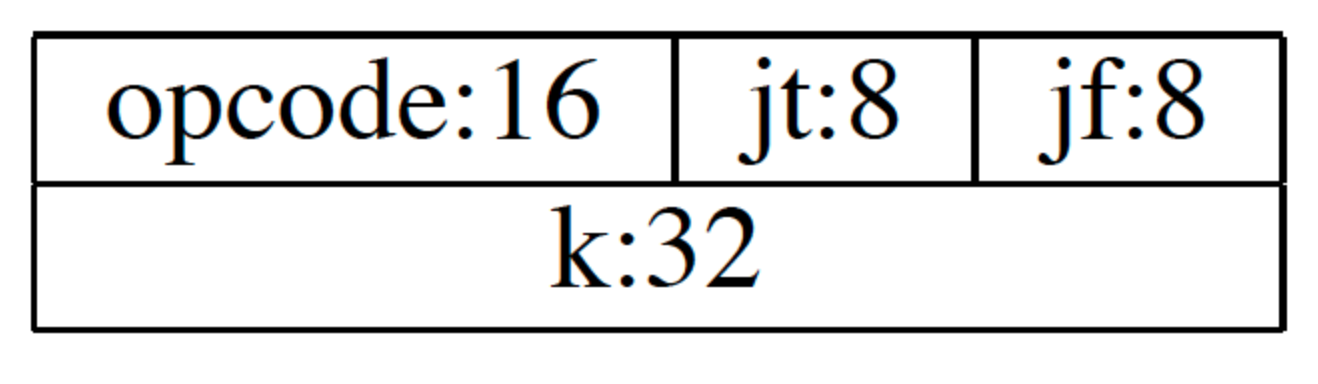
其中:
- opcode 表示指令类型和寻址模式;
- jt 和 jf 用来表示当结果为 true 或者为 false 时要跳转到下面第几条指令;
- k 为通用 field,可用于多种目的 ;
下图则是当时论文设计的完整的 BPF 指令集:
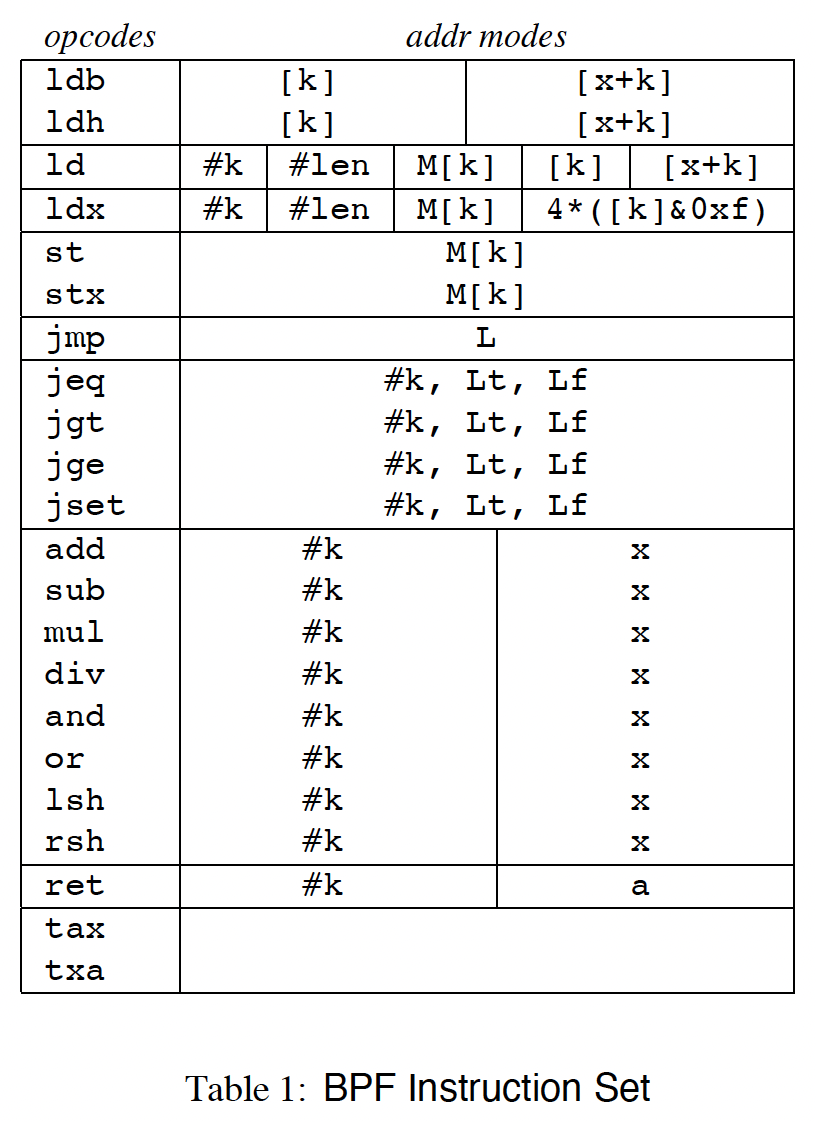
上述这种表述方式仍然是用为一种 assmbler syntax,并非最终的编码实现。
- ld / ldh / ldb 将对对应数据 copy 进 accumulator(32 /16/8),ldx 将值 copy 进 index register;index register 无法用于 packet addressing mode;如果要将包数据 copy 进 x,则必须想用 load 指令将数据 copy 进 accumulator,再通过 tax 指令将其 copy 进 x(txa 指令估计是反方向);
- 我们可以用
ldx 4 *([14] &0xf)来计算 IP 长度,即将 IP 长度计算出来后 copy 到 x 中,因为特别常用,就单独拎出来一个这个指令; - 默认所有的 value 都是 32-bit(如果不显式加后缀),且为 host order,load 指令会将其从 network order 转成 host order;
- 超出 packet 的长度的引用会触发 filter 的终止并返回 0(即丢弃 packet);
- ALU 指令(add / sub / mul …)会将用 accumaltor 的值与对应的值进行运算,并将结果写回 accumaltor;
- jump 指令将 accumulator 的值与某个 constant 进行比较,如果结果为 true(或者非零),则跳 true 分支;否则为 false 分支。由于 8-bit 的限制,最多只能跳 256 条指令。但是用 jmp 可以用 32-bit;
- return 指令用来返回 packet 有多少 bytes 被 accept。如果为 0,则说明 packet 被 reject;
BPF 的地址模式有:
用 tcpdump 来验证 BPF 指令集
单纯看 BPF 指令集会显得难以理解,让我们用一个实际的例子来看看吧。tcpdump 底层采用 libcap 来捕获 Packet。tcpdump 会利用 libbcap 将用户前端输入的过滤表达式编译成 BPF 指令并加载至内核,从而内核可以执行相应的包过滤命令。
比如,我们有这么一个 tcpdump 指令:
|
|
-d 是将编译后的 BPF 指令打印出来。此时我们将得到:
|
|
让我们逐条来分析这些指令(如果此时忘记指令内容请参考上文的那张表):
-
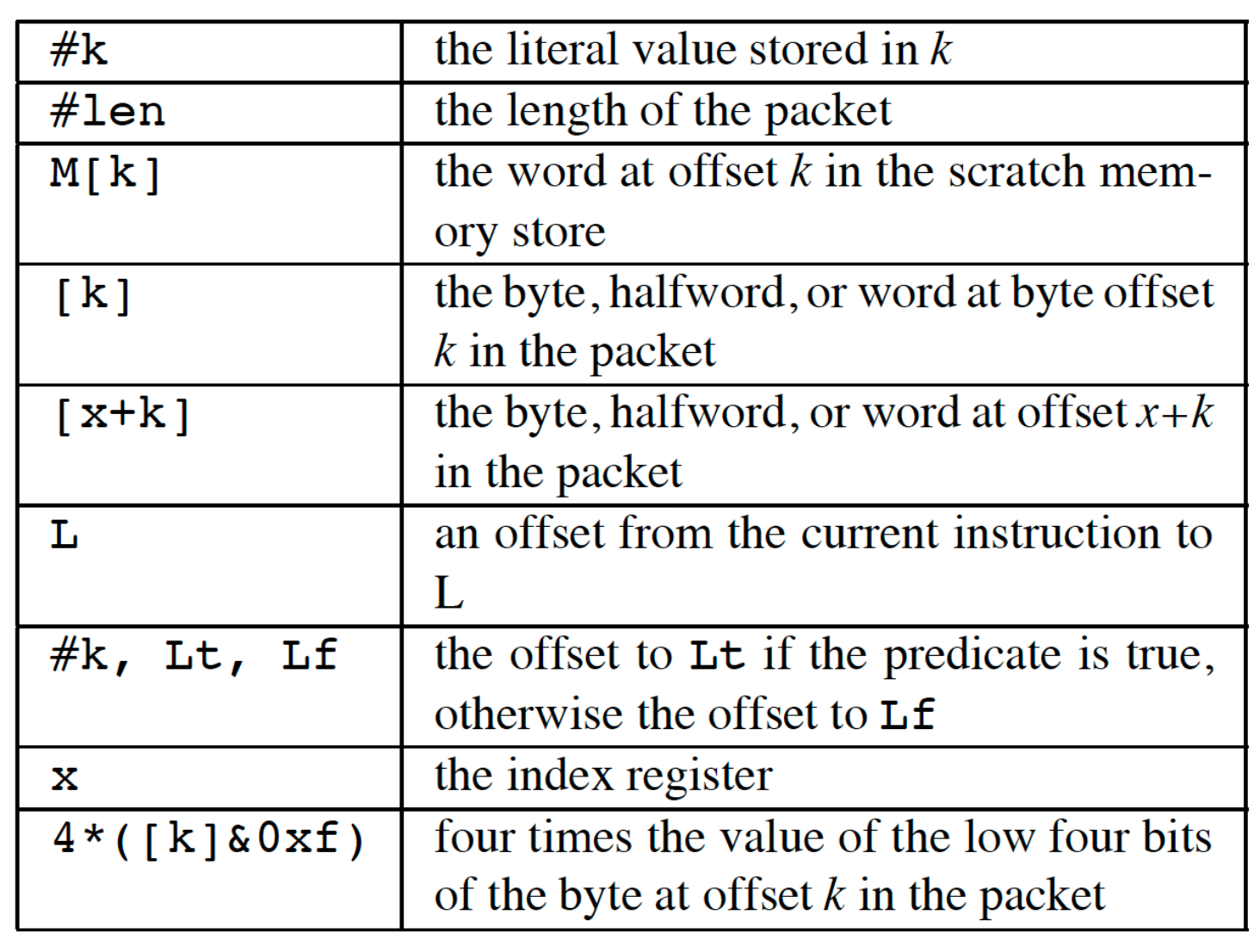
ldh [12]:由于 libcap 是监听链路层网络包,所以过滤包以一个完整的以太网 frame 为单位,加载 offset 在 12 bytes 的 half-word(2 bytes)的内容到累加器,即 EtherType 字段(可见下图); -
jeq #0x86dd jt 2 jf 8:jeq指令会将累加器的值与某个 constant 进行比较。上面加载的 half-world 内容如果是0x86dd就跳转到 2 号指令(IPv6 ),否则跳转到 8 号指令。我们假设跳转到 8 号指令(即前面序号为 8 的指令); -
jeq #0x800 jt 9 jf 19:还是指令 1 加载的 half-world 内容,如果是0x8000就跳转到 9 号指令(IPv4),否则就跳转到 19 号指令。我们假设跳转到了 9 号指令; -
ldb [23]:执行到这里说明已经是 IPv4 packet 了,我们加载 offset 在 23 bytes 的 half-world 的内容到累加器。这里稍微解释一下为什么是 23: -
jeq #0x6 jt 11 jf 19:判断当前 IPv4 Packet 是否为 TCP 协议,如果是则跳至 11 号指令,否则跳至第 19 号指令,假设我们跳自第 11 号指令; -
ldh [20]:通过上面的分析,我们知道这是加载从以太网头部开始的第 21 和 22 个 byte 到累加器,即 Flags 和 Fragment Offset 的字段; -
jset #0x1fff jt 19 jf 13:由于 IPv4 的 Flags 字段只有 3 个 bit,而我们是想得到 Fragment Offset,所以只需要看低 13 位。jset指令会将累加器的内容与某个常量进行与操作,如果最终得到的值不为 1 则为 true,否则为 false。放在这个当前这个语义,则表示:如果此时 fragment offet 不为 0,则跳至第 19 号指令,即结束匹配;否则跳自第 13 号指令(我们需要第一个分片信息)。假设我们跳自第 13 号指令; -
ldxb 4*([14]&0xf):这条可以看出是一个特殊指令,即快速计算 IPv4 的长度,并将计算得到的值放至 x 中,即 index register; -
ldh [x + 14]:x即上面指令计算得到的 IPv4 长度,14 则是以太网头部内容,所以 offset 为x + 14为 TCP 包开始的位置,加载 2 个 byte 到累加器,即 Source Port 字段; -
jeq #0x1bb jt 18 jf 16:#0x1bb即为 443 的 16 进制。这条指令就是判断 Source Port 是否为 443,如果则表示匹配成功,返回一个非 0 值,否则跳至第 16 号指令继续匹配 Destination Port。后续指令都是很类似,此处就不再继续展开解释。

从 cBPF 演进到 eBPF
BPF 技术从最早的 BSD 逐渐演变到 Linux 内核并以此为基础提供了 tcpdump 这类广为人知的网络包调试工具(下述时间表参考自 BPF: the universal in-kernel virtual machine 和 BPF Performance Tools 一书):
-
Jay Schulist 在 Linux 2.5 中将 BPF 引入 Linux;
-
Eric Dumazet 给 BPF 解释器增加了 JIT,从而大幅提升执行效率;
-
Will Drewry 在 Linux 3.4 中为 seccomp 增加了 BPF,这是 BPF 第一次运用在网络领域之外,显示出 BPF 可作为一个通用执行引擎的潜力;
也就是说,Linux 内核老早就有了一个虚拟机,只不过这个虚拟机比较简单,覆盖的内核模块(Hook 点)也比较有限,总的来说,这是一项相对很冷门的技术。
而这一切被 Alexei Strarovoitov 这位内核黑客改变了:
-
2014 年初,Alexei Strarovoitov(当时他在 PLUMgrid 公司正在研究一种新的 SDN 方案) 向 Linux 社区提交了重新实现 BPF 的内核补丁,这可以说是 eBPF 最初的实现:
- 新的设计针对现代硬件进行了优化,能生成比旧的 cBPF 更高效的代码;
- eBPF 扩充了 cBPF 的寄存器数量,将原有的 2 个 32 位寄存器增加到 10 个 64 位寄存器。由于寄存器数量和宽度的增加,用户可以使用更多的函数参数交换更多的信息,从而编写更复杂的程序;
这是 20 年来 BPF 的第一次重大更新,此举也将 BPF 扩展为一个通用的虚拟机。
-
后续 Alexei Strarovoitov 和 RedHat 的内核工程师 Daniel Borkmann 通力合作,将 eBPF 合入内核,又创造了 BPF Map 和 Verifier 机制;
-
社区又为 BPF 设计了一个新的系统调用:
bpf(2),从此用户层可以通过这个关键的系统调用来控制 BPF 的各种行为;
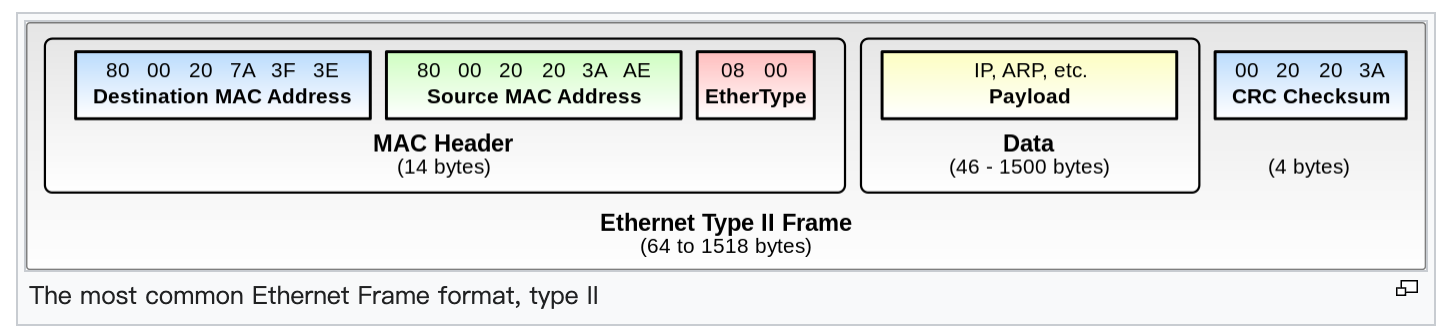
经过社区的不懈努力,eBPF 演化出如下的架构:
这是一个庞大的系统生态工程,需要:
-
编译器生态:Clang 支持将 C 语言编译成 BPF 指令(后续 Rust 又利用这一特性可将 Rust 编译成 BPF 指令);
-
Loader 生态:目前是以内核的 libbpf 为根正苗红的 Loader 代表,也有像 cilium/ebpf 完全用 Go 实现的 Loader。总而言之,这些 Loader 底层逻辑都将转换为对
bpf(2)的调用; -
BPF Map:这是内核侧一个巨大的创新,相当于在 BPF 程序中引入一个存储系统,从而用户侧与 BPF 程序,BPF 程序之间都可以通过 Map 来实现数据的传输,从而可实现更为灵活的功能。内核支持多种不同类型的 Map,比如 Hash Map,Array Map 等;
-
Verifier:这是 BPF 相较于 Kernel Module 安全性提升的一个突出特点。正如上文所介绍,BPF 其实最终都将转换为一个 DAG,所以内核侧可以通过分析 DAG 来检测 BPF 代码是否 Safe,并对不 Safe 的 BPF 代码拒绝加载,比如:
- BPF 指令数量有上限限制;
- BPF 指令不可以有无限循环;
- BPF 指令必须在有限时间终止;
等等。理论上,只要是 Verifier 允许加载的 BPF 程序,在大多数场景运行下都能保证内核安全(而传统的 LKM 则没有这层限制或保障)。
-
JIT Compiler:进一步提升内核执行 BPF 指令的指令,这其实也是大多数解释器提升执行性能的手段;
-
内核的 Hook 点:可以说这是 BPF 能力边界提升的最大生态。随着内核的不断演进,内核越来越多的 Hook 点支持 BPF,也就是说,上层用户可以通过在这些 Hook 点注入 BPF 代码来编程内核。
-
内核的 Helper 函数:BPF 程序只能借助内核的 BPF Helper 函数来访问内核,因此 Helper 函数有点像 BPF 程序访问内核的系统调用(底层实现依赖于 BPF 的 BPF_CALL 指令)。内核通过 Helper 函数为 BPF 程序提供了一种安全访问内核的方式。Helper 函数越丰富,BPF 程序就能访问内核更多的数据或资源,就能实现更复杂的逻辑和功能。
基于 BPF 技术的项目
从当前的 BPF 生态来看,我们可以发现,大多数的 BPF 项目都基本聚集在 3 个领域:Network、Observability 和 Security。
- Network 领域:由于 XDP 技术(有不少人拿这个技术与 DPDK 来比较)的引入,我们可以实现更高性能的网络方案,比如 Facebook 基于此开发了 Katran 的高性能 4 层 LB。将 Network 和 Observability 结合在一起,Isovalent 公司开发出了 Cilium 这一强大的容器网络解决方案;
- Observability 领域:由于 BPF 可以方便地与内核各种事件源结合(kprobe、uprobe、tracepoint、USDT),因此可以提供更高性能且更全面的数据采集工具,比如 BCC 工具集和 bpftrace;
- Security 领域:目前应用还不算太多。比如 Cilium 利用 BPF 技术来实现扩展版 NetworkPolicy ;Falco 利用监测内核系统调用事件来判断是否出现安全问题(其实更像是 Observability)。这里还有一个非常值得一提就是 Google 基于 LSM 和 BPF 开发的 Kernel Runtime Security Instrumentation(KRSI),从而我们上层用户可利用 LSM 的各种 Hook 来开发各种 Security 系统(KRSI 于 Linux 5.7 合入内核)。
展望未来
写到这里,我们不由得要引用 Arnaldo Carvalho de Melo 在 LPC 2019 演讲中说的一句名言:
BPF is Eating the World, Don’t you see?
他极其乐观地表明了对 BPF 技术未来前景的看法,而后续社区的发展也无疑再验证他的这句话(比如 eBPF Foundation 的成立)。
其实,BPF 技术发展至今,仍有不少空白和棘手的领域等待着更多的人去填补,比如:
-
BPF 技术极度依赖于高版本的 Linux 内核,而 Linux 内核的轮转速度在大多数 IT 企业(就算是以快著称的互联网公司也不例外)中天生就是一件非常缓慢的事情。我们也许兴高采烈地欢呼 Linux 内核上游又增加了一个激动人心的 BPF 特性,但是却发现公司 SRE 为了业务稳定性的考量并不想让我们升级内核。Linux 内核的灰度更新是一个极其考验一个公司运维水平的事情,然后大多数公司的决策者更情愿稳定压倒一切,牺牲一点技术红利而换来风平浪静,有何不可呢 ?就这个问题,我们能不能提供一个系统化的解决方案来提升大多数公司的内核轮转频率呢,从而在底层基础设施的创新和业务稳定性中找到平衡 ?
-
虽然 BPF 程序通常不会太复杂,但是编写 BPF 程序仍然要求用户有一定的内核知识(至少得知道内核各种 Hook 点和数据结构),这对于大多数人来说仍是一件不小的学习量,我们是否能进一步降低这个编程门槛呢 ?能否让大多数对 BPF 技术感兴趣的开发者只需要花一天时间看看文档就能编写出生产可用的 BPF 程序 ?
-
BPF on K8s 目前还没有太多相关产品,个人认为还存在不少可以创新的空间;
-
BPF 的 CI/CD 目前仍然没有标准,我们是否能够基于 BPF CO-RE 特性来像 Docker image 一样打包 BPF 程序 ?
等等,只要我们愿意思考,总能找到创新的点子。
BPF 技术需要更多有创意的工程师持续贡献新的想法(内核层的进一步增强、用户侧更加有想象力的使用场景等等),我坚信,这门技术在不远的未来一定会有更大更强的生命力。