利用云上对象存储开发高性能数据分析服务(笔记) | 读读论文
Contents
论文地址
今天来读的是由德国慕尼黑工业大学(TUM)的学者们在 VLDB 2023 上发表的一篇论文 Exploiting Cloud Object Storage for High-Performance Analytics 。这篇论文之前听我的同事 Weny 老师讲过,后面自己又重读了一遍,觉得很有价值,特别写点笔记记录一下。
想解决什么问题
利用云上的对象存储来开发 OLAP 服务,这在今天看来已经成了主流的技术趋势(看看 2020 年 Snowflake 上市时的疯狂)。究其本质,利用云对象存储来设计存算分离的 OLAP 同时满足了算力弹性和降低存储成本的优势。更广泛地说,这一技术趋势在处理 AP 型负载时有着极大的优势。
但是,云上的对象存储相比于传统的本地 NVMe 存储有着很大的差异,尽管二者的带宽正日渐缩小。这篇论文基于云上对象存储和 io_uring 为 OLAP 设计并开源了 AnyBlob(类似于 OpenDAL ),一个集成多个云对象存储的 download manager,能做到即降低 CPU 使用率又提升了吞吐。论文描述其 AP 服务 Umbra 在装配了 AnyBlob 之后,即使没有缓存,也能与将数据缓存于本地 SSD 的数仓达到类似的性能。
云上对象存储的特点
成本
基本上所有的云对象存储的成本组成都是非常相似的,基本上就是:
-
按存储容量收费
比如标准的 S3 在 us-east-2 区域提供每月 $0.023/GB 的收费模式(实际上 S3 针对存储容量的不同会有一个简单的阶梯收费),也就是一个月存储 1 TB 的数据费用约为 $23.55。一般而言,如果你观察到云上数据库的每月 1 TB 存储费用处于 $23.55 范围内或同一数量级,那基本可以断定这个云上数据库服务大概率采用了对象存储作为底层存储。
再将 S3 与 AWS 块存储 EBS 相比较,我们将发现 AWS EBS 有如下缺点:
-
费用较贵:目前 EBS gp2 类型(现在更推荐使用 gp3)的 SSD 每月 1 TB 存储费用为 $102.4,很明显与 S3 的存储费用不是一个数量级。HDD 类型的块存储虽然费用上与 S3 类似,但带宽非常有限。大多数 EC2 都不自带本地 SSD,而带有本地 SSD 的 EC2 价格都会比较昂贵(可参考我之前写的 AWS EC2 机型漫游小指南);
-
存储与具体的 EC2 实例绑定:一般情况下 EBS 只能被挂载在同一个 EC2 上,除非使用更贵类型的
io1或者io2类型来实现 Multi-Attach,在大容量存储场景下性价比较低; -
EBS 有容量上限:以 gp2/gp3 为例,一般 EBS 上限是 16 TiB,这对存储扩容带来了更多管理成本;
-
-
API 费用
以 S3 的 us-east-2 区域为例:
- PUT/COPY/POST/LIST 请求:每 1000 个请求 $0.005,即每百万次调用
$5; - GET/SELECT 以及其他请求:每 1000 个请求 $0.0004,即每百万次调用
$0.4;
即读比写要便宜一个数量级。仔细想一想也挺符合直觉的,写的话要涉及很多关键链路并且实际产生存储成本,读的话通常更多的是带宽和一些缓存开销,相对会比写 “轻” 一些。
- PUT/COPY/POST/LIST 请求:每 1000 个请求 $0.005,即每百万次调用
-
跨 region 网络传输费用
以 S3 的 us-east-2 区域为例:
-
从互联网将数据传入 S3 不需要流量费
-
AWS 服务内的同一 region 内访问 S3 不需要流量费
也就是说,同一 region 内,访问对象存储的成本与其请求对象的大小无关,下载 1KiB 大小的对象与下载 1 TiB 大小的对象成本相同,只需要一个 HTTP GET 请求的费用;
-
AWS 服务内的跨 region 访问 S3 需要每月 $0.02/G
-
将 S3 的数据传输到互联网需要每月 $0.09/G(有一定的免费额度)
-
以下这个图列出了不同云对象存储价格模型的比较,可以看出成本其实都非常接近(除了 Oracle Cloud 对象存储的每百万次写费用是个异类):
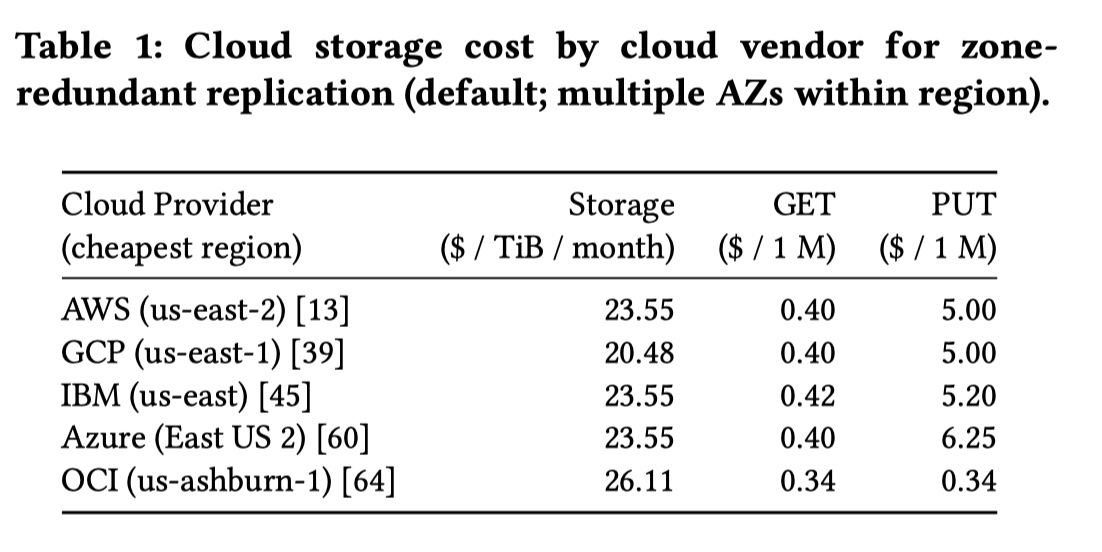
个人经验:在大多数场景里,存储容量的成本增长相对会较稳定且可预测,流量费某种程度又可以避免(比如尽量减少跨 region 间访问),所以 API 费用是规模化应用下的成本大头。
延迟
使用云上对象存储之后,基础延迟肯定是变高。论文作者做了下面几个实验来测试延迟:
-
区分总延迟和首字节延迟(即调用方接收到第一个字节所需要的时间);
-
请求不同大小的数据(1 KiB /1 MiB / 4 MiB / 8 MiB / 16 MiB / 32 MiB);
-
区分第一次请求和连续 20 次请求的延迟,以此来模拟热访问;
-
持续几周时间从一组对象中获取单个对象,每次一个请求,以分析访问性能的趋势。性能用带宽(数据量除以时间)进行衡量;
这一节比较有意思,我了解到不少之前没有关注过的对象存储的底层细节,比如有这么几个有意思的结论:
-
小尺寸请求:首字节延迟与总延迟差不多,此时 RTT 占比会更大。随着请求数据大小的增加,首字节延迟变化不大;
-
大尺寸请求:带宽是更主要的瓶颈。当达到带宽瓶颈后,性能将不会提升;
-
热访问:由于对象存储内部也有缓存机制,因此总延迟和首字节延迟在热访问场景下总会更低;
-
Noisy neighbors 现象:持续 8 周地获取单个对象,其带宽在不同的时间段内具有很大的差异。特别在周末性能会更高,这很有可能是因为此时其他客户的使用量需求较低导致的。这是一个非常有意思的发现。我们总认为对象存储是海量且性能稳定的存储,但实际上仍会受到云上其他租户的影响;
吞吐
在典型的 OLAP 场景中,吞吐比延迟更为重要,因为我们总是希望能尽可能多地传送数据进行分析。目前来看,云对象存储的吞吐量与对应的云实例带宽类似,即云实例带宽限制了你能访问对象存储的带宽。以 AWS 为例,论文使用了最高可以有 100 Gbit/s 带宽的 EC2 c5n.18xlarge ,同时启动 256 个线程来并发进行 16 MiB 大小请求。结果发现在 AWS 的 eu-central-1 区域能实现 80~90 Gbit/s 的中位带宽。
还有一个细节,冷对象也可以实现高带宽,冷热访问对带宽影响不大。
最佳请求大小
我们对对象存储的请求可以是完整的单个对象,也可以请求单个对象的某一部分字节范围(Range Get)。不同的请求大小将会影响成本和性能:
- 影响成本:更大的请求大小意味着更低的 API 调用;
- 影响性能:小请求有利于小表数据;
论文根据实验给出了针对 OLAP 场景的最佳请求大小:8~16 MiB。
加密
以 AWS 为例。如果在 S3 上使用 HTTPS,那么将比采用 HTTP 多花 2 倍 CPU 资源。但在 S3 上使用 HTTPS 显得有些多余,因为:
- 跨 region 的流量默认由网络基础设施自动加密;
- 同一个 region 内,由于 VPC 隔离,其他用户无法拦截 EC2 与 S3 网关之间的流量;
比流量加密更重要的是,我们更需要 S3 上的数据落盘加密(encryption-at-rest)。
Request Hedging
使用对象存储的时候,会存在一定比例的尾部延迟(Tail Latency)(或者说慢请求),即有些请求在没有任何通知的情况下将丢失。为了缓解这一情况,我们需要 Request Hedging(这个有点难以翻译,直译是请求对冲),即重新启动无响应的请求。其实我理解就是请求重试。
设计更好的数据获取模型
基于上文的分析,我们可以用最佳的请求大小并发跑多个请求来充分利用云实例的带宽。我们可以用下面这个简单的模型来计算并发跑多少请求才合适:
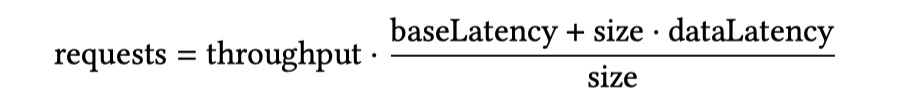
-
size:请数据请求大小,此处以适合 OLAP 的最佳请求大小 16 MiB 为例; -
throughput:即云实例的带宽,比如 100 Gibit/s;baseLatency:基础延迟,论文用上文小尺寸请求的实验估算出这个值中位数约为 30 ms 左右,其实本质上就是 RTT;
-
dataLetency:单位数据量的延迟,论文用 16 MiB 大小的请求实验估算这个值的中位数是 20 ms/MiB,很明显这个延迟与带宽强相关;
我觉得论文原始的公式写法有点不直观,其实本质是:
|
|
其中每个请求的带宽可以下面这个公式获得:
|
|
而延迟则是:
|
|
将上文数据带入可以算出延迟在 16 MiB 情况下为:350 ms。由此可得每个请求带宽为:
|
|
假设吞吐为 100 Gbps,那么并发请求数不难算出约为 261 个:
|
|
论文推荐最佳并发请求数是 200~250 个,与上文的计算大体类似。
AnyBlob 的设计
AnyBlob 的设计感觉就是充分利用了内核 io_uring 的能力来提升并发下的异步能力,并结合对象存储的一些特点做了优化,这个思路感觉也是大多数同行的思路。
一点点启示
Snowflake 模式的成功基本上就标志着利用云上基础设施来做一个大型数据库是完全可行的事情,这基本也是这几年所有新创数据库公司一致的技术路线。以前人们需要基于操作系统和硬件的特点来设计数据库,未来则必需基于 Cloud 的特点来设计新的数据库了,对象存储就是新的硬盘。