Policy DSL 的思考
Contents
什么是 Policy
用简单的语言解释就是 Policy 可认为是一系列 if 语句:
|
|
根据具体的业务场景,condition 可能会出现很多情况,从而 if 将出现很多分支。命中每一个 if 分支,就相当于作出了一次 Policy 的决策。为了跟已有的系统解耦,这个 if 语句不做具体的动作,只返回决策数据,业务系统拿到这个决策数据后再进行下一步动作。这个决策后的输出数据需要根据具体的业务来进行定义。
对于使用 Policy 的其他组件或服务来说,执行 Policy 决策就相当于执行一个函数(比如上文的 eval),并且给这个函数一个外界的输入。Policy 内部也需要维护着与 condition 相关的内部数据。所以,使用 Policy 的逻辑可类似于:
|
|
类似于上文的策略和决策的逻辑在几乎所有的业务系统都随处可见,且与对应的业务紧密结合。
如果使用 Policy As Code 的方式,上面的 Policy 的逻辑就又可以变成:
|
|
此时 code 用某种 DSL 描述了 eval 内部的各种 if 语句。此时用户界面从与具体业务所使用的编程语言变成了某种更抽象的 DSL。具体的业务系统所直接接触的是 DSL,或者是这个 DSL 的衍生产物(比如 DSL 编译成 WebAssembly)。借用 OPA 的一张图(关于 OPA 的介绍,可参考这篇文章)可表示为:
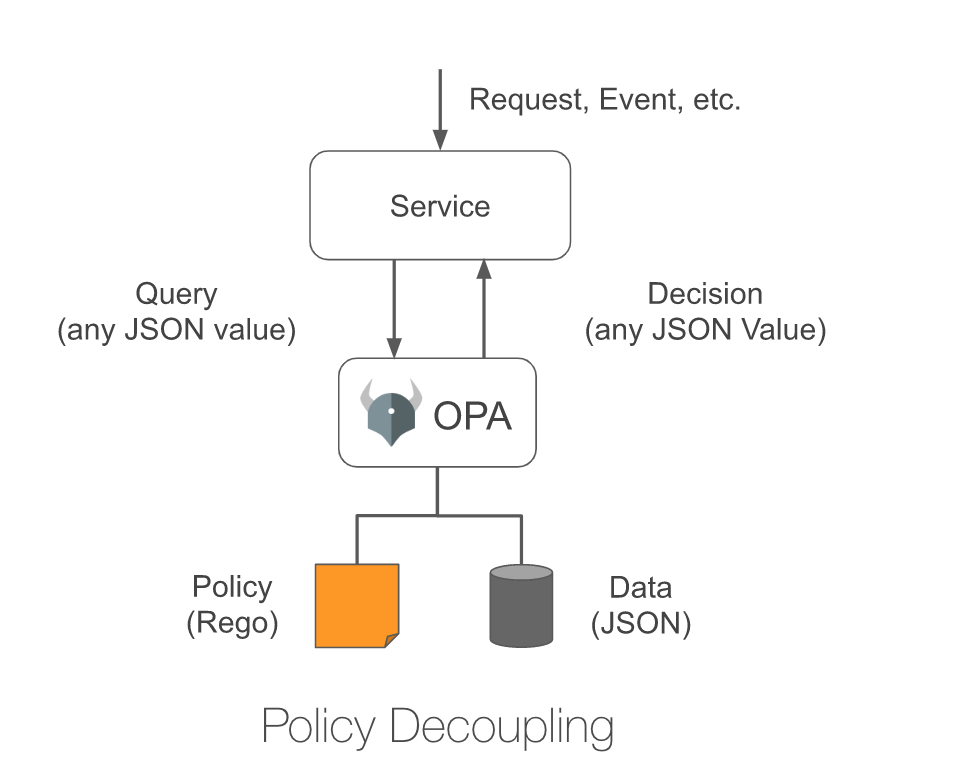
这样一来,业务系统只需要保持一个统一的 API 并定义定义好决策后返回的数据结构,剩下和 Policy 相关的具体逻辑用 DSL 来进行描述。
这么设计的好处有:
- 解耦:当 Policy 发生改变时,只需要修改 Policy DSL,业务系统只需要加载新的代码即可,无需修改其他逻辑;
- 代码特性:可测试、可版本化、更抽象等等;
几种 Policy Languge 的设计
OPA Rego
基本设计
Rego 语言采用的是声明式的设计,用户只需描述规则而无需关注规则是如何求解的。按照设计者的说法 [1]:
Syntax should reflect real-world policies.
Rego 语言是源于 Datalog(Prolog 的另一个变种),所以 Rego 处处可见逻辑编程的影子。Rego 主要有以下几类抽象:
-
Rule 表达式
可认为 Rego 代码都是由一系列 Rule 表达式组成,每一个 Rule 表达式就类似于一个 if 表达式。
如果我们想表达:
如果输入数据的
method字段为GET,返回true,反之返回false。用 Rego 表达即为:
1 2 3allow { input.method == "GET" }此时
allow的返回值为true或false。每一个 Rule 表达式都包含一个 head 和 body,比如上面的例子allow就是 head,{..}就是 body。在 Rego 中,对一个 Rule 求值就相当于生成一个 Virtual Documents,其实就是生成一个 JSON 对象,因此 Rule 的求值结果可以是简单的 bool 值、JSON 数组 和 JSON Object 。
每一个 Rule 的 body 内部的所有条件为布尔与的关系,即最终的值需要满足 body 内的所有条件,比如我们想表达:
如果输入数据的
method字段为GET且url不为example.com,返回true,反之返回false。用 Rego 表达即为:
1 2 3 4allow { input.method == "GET" input.url == "example.com" }如果想表达布尔或的关系,需要写多条 head 一样的 Rule,比如:
1 2 3 4 5allow {...} allow {...} allow {...}上面的 3 条 Rule 将构成一个布尔或的关系,以最先满足 Rule 条件的表达式求值为整体 Rule 的值。比如我们想表达:
- 如果输入数据的
method字段为GET且url不为example.com,返回true,反之返回false; - 如果输入数据的
host字段为alipay.com,返回true,反之返回false;
用 Rego 表达即为:
1 2 3 4 5 6 7 8allow { input.method == "GET" input.url == "example.com" } allow { input.host == "alipay.com" } - 如果输入数据的
-
非显式 Iteration
在 Rego 中没有显式的循环结构,即有类似
for或者while的结构,而是使用另一种非显式的 Iteration。假如我们需要给 Policy 输入如下的内部数据:
1 2 3 4 5 6 7 8 9 10 11 12{ "allow_operations": [ { "method": "GET", "resources": ["api", "job"] }, { "method": "PUT", "resources": ["daemonset"] }, ] }如果我们想表达:
allow_operations列表中存在一个成员,其resource字段存在api这个资源。如果是用命令式的编程语言(比如 Go)来表达,就是一个 for 循环:
1 2 3 4 5 6 7 8 9 10func exist_api_resource() { for _, op := range allow_operations { for _, r := range op.resources { if r == "api" { return true } } } return false }在 Rego 中,只需要这样表达:
1 2 3 4exist_api_resource { some i,j allow_operations[i].resource[j] == "api" }some关键字用来定义 Rule 内部的局部变量,如上定义的i和j。而:1allow_operations[i].resource[j] == "api"其实等价于一个 for 循环。如果有多个
i和j满足条件,则多个满足条件的值都将被绑定到变量上。如果将i和j展开,将输入所有满足条件的i和j。如果不关心具体的变量,上面的 Rego 语句可简化为:
1 2 3exist_api_resource { allow_operations[_].resource[_] == "api" }在这种方式下,如果想表达 For-All 语义,比如:
所有的
allow_operations都不存在一个成员其resouces列表为pod。如果用 Go 来表达,可以是:
1 2 3 4 5 6 7 8 9 10func no_pod_resource() { for _, op := range allow_operations { for _, r := range op.resources { if r == "pod" { return false } } } return true }Rego 无法直接表达 For-All 的语义,需要依赖于
not表达式(或者是用 comprehension,这个暂时不说):1 2 3 4 5 6 7no_pod_resource { not exist_api_resource } exist_pod_resource { allow_operations[_].resource[_] == "pod" }exist_api_resource表达了存在pod这个 resource,而:1not exist_api_resource表达是一个非的条件,即 “不存在一个为
pod的 resource”。 -
模式匹配
Rego 的官方文档没有 Pattern Matching 这个术语,但感觉概念是一样的。在 Rego 中,用
=来实现模式匹配的能力。=结合了赋值和比较。比如:
1[x, "world"] = ["hello", y]这个表达式执行之后,
x将被赋值hello,而y将被赋值world。对
=表达式进行求值的最终效果是满足两边等式,如果等式两边存在变量,变量将被赋值满足条件的值。结合
=和非显式的 Iteration,可以实现比较复杂的比较:1sites[i].servers[j].name = apps[k].servers[m] -
Comprehension
Rego 的 Comprehension 和其他编程的 Comprehension 的形式和概念是一致的:根据一定的规则生成数据。这里的规则和 Rule 表达式的形式是差不多的,比如有如下输入数据:
1 2 3 4 5 6 7 8 9 10sites := [ { "region": "east", "name": "prod" }, { "region": "west", "name": "smoke" }, ]如果想表达:
筛选出所有
region为west的数据的name。用 Rego 的 Comprehension 可表达为:
1 2region := west name := [ name | sites[i].region == region ; name := sites[i].name ] -
Package
在 Rego 中,每条 Policy 都定义在 Package,此处的 Package 类似于包管理机制。比如 [1] 所举的例子:
developer 团队可在
developerPackage 中定义自己的准入策略:1 2 3package developer allow { ... }security 团队可在
securityPackage 中定义自己的准入策略:1 2 3package security allow { ... }主入口可分别引用这两个 Package,只有同时满足这两个 Package 定义的准入策略来允许进入系统:
1 2 3 4 5 6package main allow { data.developer.allow data.security.allow } -
基于 JSON 的输入输出
Rego 将 JSON 作为数据(同理可应用于 YAML)输入输出的一等公民 [2]。Rego 的对数据的访问都是基于 JSON 的数据结构,比如:
1 2 3 4 5 6 7 8 9 10 11{ "request": { "method": "GET", "header": [ { "key": "foo", "value": "bar" } ] } }-
访问
method字段即为:request.method; -
访问
header字段的某一个成员的key:request.header[_].key;
-
Rego 好不好用
使用了 Rego 一段时间的感受:
Rego 的设计借鉴了逻辑编程的声明式表达方式,用户只需用声明的方式表达自己的 Policy,而无需关注 Policy 的底层求值过程是一个列表遍历还是一个树的遍历,这种方式其实可以让代码表达力更强,更符合现实世界对规则的描述。Rego 对 Rule 表达式的抽象也去掉了显式的 && 或者 || 这类表达式,需要用户将代码组织成 Rule 表达式规定的形式才能实现 && 和 ||。Rego 的非显式 Iteration 通常需要和 Comprehension 结合使用,可实现表达性更好的代码(这里的表达性指的是可以写更少的代码达到同样的意图)。
但是,Rego 的 “不好用” 就在于其非主流的表达方式(个人感觉更贴近于函数式编程的模式)。大多数程序员更能适应有显式循环和经典的 conditon 表达式。这两种截然不同的表达方式导致了 Rego 语言作为一门 Policy DSL 显得并不那么好学,不好学的原因就在于你很难直接复用已经习惯的编程习惯,而要花时间去适应另一种编程范式,这导致这门 DSL 有一定的学习曲线,不利于推广。
Hashicorp Sentinel
Sentinel 语言是 Hashicorp 出品的非开源的 Policy DSL,其设计一如 Hashicorp 一如既往的作风:简单好用,就如文档 [3] 所说:
…This language is easy to learn and easy to write. You can learn the Sentinel language and be productive within an hour…
从形式上看,Sentinel 并没有引入额外的编程模式,还是使用大多数命令式编程的模型,所以用 Sentinel 写的代码和其他主流语言写的代码没有太大的差异。所以才会显得简单,学习成本极低。
基本设计
-
Rule 表达式
Sentinel 的 Rule 表达式和 Rego 语言形式上很像,但求值结果仅支持布尔值,且需要使用显示的逻辑运算符来表达与和或的关系。
比如你想表达:
你可以去和朋友玩,只要:
- 周末且没有作业;
- 非周末但是不用去学校;
用 Sentinel 语言可表达为:
1 2 3 4 5 6 7 8 9 10// A weekend is Sat or Sun is_weekend = rule { day in ["saturday", "sunday"] } // A valid weekend is a weekend without homework is_valid_weekend = rule { is_weekend and homework is "" } // A valid weekday is a weekday without school is_valid_weekday = rule { not is_weekend and not school_today } main = rule { is_valid_weekend or is_valid_weekday }main表达式最终求值的 Rule 表达式。Sentinel 语言的 Policy 同样是由各种 Policy 组成,且有一个
mainPolicy 来作为最终求值的结果。 -
Imports 设计
和其他大多数编程语言差不多的包管理方式。
-
内置数据结构
支持和 Python 类似的 List 和 Map,且使用接口和语法糖也差不多;
-
Conditions 语句
支持几种典型的 if 语句:
1 2 3 4 5 6 7 8 9 10 11 12 13if condition { // ... } else { // ... } if condition { // ... } else if other_condition { // ... } else { // ... } -
循环结构
支持好几种典型 for 循环,比如:
1 2 3 4 5 6 7 8 9count = 0 for [1, 2, 3] as num { count += num } list = [] for { "a": 1, "b": 2 } as name { append(list, name) }
综上所述,sentinel 语言基本是将日常的编程习惯(比较贴近 Python)做了一层较小的抽象,用户使用的时候只需要引入极少的概念就可以立刻写代码,友好度极好。
Google CEL
Google CEL(Common Expression Language)比 Rego 和 Sentinel 语法集更小的 DSL,采用 Protocol Buffer 作为数据输入格式。
备注:这块研究极少,后续有空再补充一下。
Google CUE
CUE 项目 是基于 Google 内部 Borg 系统所用 GCL 语言启发而开发的语言,本质上还是用 Infra as Code 的方式来解决配置部署的复杂问题,进而提效。
本人没有对 CUE 做过太多深入的研究,不过 Twitter 上曾经看到有人对 CUE 和 Rego 做了一次比较,不过这个比较不算太客观,毕竟是 CUE 内部自己做的。
备注:这块研究极少,后续有空再补充一下。
OSO polar
oso 是一个用 Rust 写的 Policy Engine,设计理念基本与 OPA 一致,这里也可以看到 OPA 社区对其的评价 。从功能上来说,oso 目前还远不如 OPA 功能丰富,但是从 Policy 语言设计来看,Polar 语言比 Rego 语言要更容易懂,但目前似乎还只支持布尔表达式的判断。
顺便提一下,不同 OPA 把 Rego 语言编译成 wasm binary 的做法,oso 支持 wasm 的方式是将自己整个 policy engine 编译成 wasm binary,从而直接支持 wasm 形态运行,这也是用 Rust 的一个好处(wasm 的支持远比 Go 要好)。
备注:这块研究极少,后续有空再补充一下。
Policy Language 应该有哪些特性
通过这段时间使用 OPA Rego 的经验,设想了 “理想的” Policy Language “可能” 是怎么样的:
-
易用性
易用性在于用户使用 Policy DSL 不需要引入过多额外的非主流概念,最好能符合大多数用户编程习惯(比如 Java/Go/Python/C++)。像 Rego 这种大刀阔斧的做法比较冒险,用户的教育成本较高。
-
声明式
个人感觉 Rego 声明式的设计值得借鉴,非显式的 Iteration 可以写出表达力更强的代码,用户不需要显式写太多的 for 循环一类的代码,但是 Rego 的声明式表达并不是特别好懂。所以是否存在一种折衷的设计:既可以声明式地表达策略,但是又无需用户有较大的学习成本。
-
高性能
Policy Engine 大多数出现在系统的热点路径上(比如 AuthZ 的场景),所以性能相当重要。在 OPA Rego 代码的编译中,会对规则建立索引,对一些存在遍历的过程转换成一个相对时间复杂度较低的树的遍历(比如 Rule Indexing 和 Partial Evaluation)。类似的优化策略可以借鉴。最好这种优化策略可以自动发生在编译或者运行阶段,用户无需过于关注。
-
支持多种输入输出数据
像 Rego 原生支持基于文本的 JSON 的数据格式,但是在有对性能和体积有要求的场景,基于二进制的数据格式(比如 Protocol Buffer)将更有优势。因此,支持多种数据输入形式的 DSL 将更为通用。不同的数据格式有着统一的数据访问方式。
-
模块抽象
这里的模块抽象指的是可以将 Policy 代码可以有类似于 Package 或者 Libary 的机制。不同人开发的 Policy 模块可以进行灵活的组合形成更丰富的策略。
-
没有 side effect
Policy Engine 应该只做策略决策,而不应该做太多决策外的动作。理论上,一段 Policy DSL 执行后不会有其他 side effect,对于同样的代码,相同的输入一定得到相同的输出,求值的过程不会导致系统的其他状态发生变化。
-
将 DSL 编译成 WASM
OPA 支持将 Rego 编译成 WASM,从而可以让 Policy 获得跨平台的特点:由对应平台的 WASM runtime 加载执行得到结果。而且,将 Rego 编译成二进制形式的 WASM 字节码后,执行性能要比 Go 解释执行要快非常多。随着 WASM 应用越来越广泛,也许将 Policy DSL 编译成 WASM 将成为一个标配。